

Contoh kasus.
Seorang peneliti ingin mengetahui apakah terdapat hubungan antara tingkat pendidikan seseorang dengan partai pilihannya.
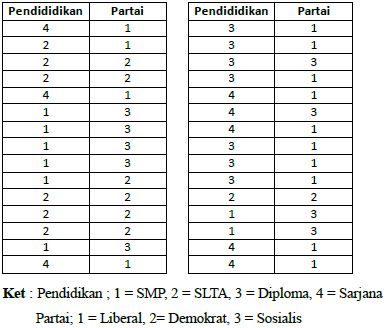 |
| Data Pendidikan dan Partai Pilihan |
- Klik Analyze>Descriptive Statistic>Crosstab
- Masukkan variabel pendidikan ke dalam Colomn (s)
- Masukkan variabel partai ke dalam kolom row(s)
- Klik tombol statistic dan pilih opsi Chi-square dan Phi and Cramer's V
 |
| Uji Chi-square Test |
 |
| Uji Crammer's V |
Hipotesis :
H0 = Tidak terdapat hubungan yang signifikan antara tingkat pendidikan dengan partai pilihannya
H1 = terdapat hubungan yang signifikan antara tingkat pendidikan dengan partai pilihannya.
Kriteria uji.
Tolak hipotesis nol (H0) jika nilai signifikansi < 0.05
Oleh karena nilai p-value crammer's V sebesar 0.000 < 0.5, maka kesimpulannya adalah terdapat hubungan yang signifikansi antara tingkat pendikan dan partai pilihannya.
Keterangan.
Crammer's V lebih tepat digunakan untuk tabel kontigensi lebih dari 2 x2 sedangkan statistik Phi lebih diajurkan untuk tabel kontigensi 2 x 2.
Baca Juga :
2. Uji Mcnemar
3. Uji Friedman
Referensi :
Antonius,R. (2003).Interpreting Quantitative Data With SPSS.London New York: Sage Publications
Elliot,A.c
and Woodward,W.A. (2007). Statistical Analysis Quick References
Guidebook: with SPSS Example.London New Delhi: Sage Publications
Einspruch,E.L. (2005). Intoduction Guide to SPSS for Windows 2nd.London: Sage Publications
Field,A. (2009). Discovering Statistics Using SPSS 3rd. London: Sage Publications





































{kind=link}
{kind=link}