"Analysis of variance is statistical technique used to determining whether samples come from populations with equal means. Univariate analysis of variance employs on dependent measure, whereas multivariate analysis of variance compares samples based on two or more dependent variables,"( Hair, Anderson, Tatham, Black, 1995).
Analisis varians adalah teknik statistik yang digunakan untuk memutus apakah sampel yang berasal dari populasi mempunyai mean yang sama. Analisis univariat menggunakan satu sampel dependen, sedangkan analisis multivariat membandingkan satu atau lebih variabel dependen.
Ketika perbandingan rata-rata melibatkan paling sedikit tiga kelompok data, maka dapat digunakan analisis varians. Analisis dengan satu faktor disebut One-Way Anova, analisis varians dua faktor disebut Two-Way Anova dan analisis tiga faktor disebut Three Way-Anova.
Contoh kasus
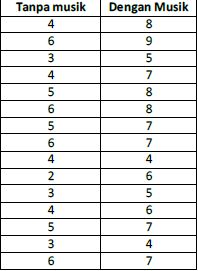
Seorang manajer supermarket ingin mengetahui apakah terdapat perbedaan jumlah pengeluaran antara jenis kelamin, dan tipe berbelanja. Jenis kelamin dibagi 2 yaitu wanita dan laki-laki. Tipe berbelanja dibagi 3 yaitu : tipe 1 (sebulan sekali), tipe 2 (sebulan 2 kali) dan tipe 3 (sebulan >2 kali).
 |
Data Input
|
NB. Jenis kelamin : 1 = wanita, 2 = laki-laki, Tipe belanja : 1 = sebulan 1 kali, 2 = sebulan 2 kali, 3 = sebulan > 2 kali
Langkah-langkah analisis :
Klik Analyze>General Linier Model>Univariate
- Masukkan Jumlah Belanja ke Dependent Variable
- Masukkan variable Jenis kelamin, tipe berbelanja ke kolom Fixed Factor
- Klik Option, pilih Homogenity test dan Descriptive statistics
- Blok Overall, Jenis kelamin, tipe berbelanja dan pindahkan ke kolom Display mean for
- Klik Save, pilih Standardized
- Klik Continue, kemudian OK
Hasil output Analisis varians dua arah (Two Way-Anova) :
 |
Between Subject Factors
|
Tabel between subject factors menjelaskan tentang banyaknya responden per kategori, jenis kelamin dan tipe berbelanja. Responden berjenis kelamin wanita sebanyak 15 responden, dan laki-laki 15 responden. Sedangkan tipe berbelanja ada 3 kategori : tipe belanja 1 bulan sekali ada 10 responden, sebulan 2 kali ada 10 responden dan sebulan > 2 kali ada 10 responden.
 |
Deskripsi Statistics
|
pada tabel Descriptive statistics di atas menggambarkan rata-rata dan standar deviasi jumlah pengeluaran dan tipe belanja. Untuk laki-laki mengeluarkan belanja dengan rata-rata lebih besar dibandingkan wanita. Laki-laki mengeluarkan belanja dengan rata-rata sebesar 3.152.66,67 juta sedangkan wanita hanya 2.452.666,67 juta perbulan.
 |
Levene's Test Of Equality of error variances
|
Tabel Levene's test dilakukan untuk menguji homogenitas varians yang merupakan asumsi yang harus terpenuhi dalam analisis varians. Nilai F diperoleh sebesar 0,557 dengan signifikansi 0,731. Karena nilai signifikansi 0,371 > 0,05 maka terbukti bahwa kedua kelompok memiliki varians yang sama atau tidak ada perbedaan yang signifikan antara kedua kelompok.
 |
Test of Between subjects Efffects
|
Pada tabel Test Between-Subject Effect merupakan tabel yang mempresentasikan hasil hipotesis. Dapat dilihat F sebesar 32,611 dan nilai p-value untuk kategori jenis kelamin sebesar 0,000 < 0,05 maka kesimpulannya terdapat perbedaan yang signifikan antara wanita dan laki-laki untuk jumlah belanja tiap bulan.
Untuk kategori tipe belanja, diperoleh nilai F sebesar 30,056 dengan p-value 0,000 < 0,05 sehingga terdapat perbedaan rata-rata jumlah belanja diantara tiga tipe belanja (sebulan sekali, sebulan 2 kali dan sebulan >2 kali)
Untuk melihat apakah ada perbedaan jumlah belanja dari faktor jenis kelamin dengan tipe belanja, dapat dilihat pada nilai p-value yang dihasilkan. Diketahui nilai p-value untuk Jeniskelamin*tipebelanja sebesar 0,005 < 0,05 yang artinya terdapat perbedaan yang signifikan jumlah belanja antara jenis kelamin dan tipe belanja.
 |
Grand Mean
|
Tabel Grand Mean menunjukkan rata-rata pengeluaran jumlah belanja secara keseluruhan responden, yaitu 2.802.666,667 juta/bulan dengan interval confidence 95% terletak diantara 2.676.171,59 juta - 2.929.161,743 juta.
 |
Deskripsi Mean Variabel
|
Tabel Jenis kelamin, tipe belanja diatas dan Jenis kelmain*tipe belanja merupakan output yang sama interpretasinya dengan tabel descriptive statistics di atas.
 |
Deskripsi Jenis Kelamin*Tipe belanja
|
 |
Estimated Marginal Means of Jumlah Belanja
|
Tabel estimated marginal means of jumlah belanja per bulan memperjelas hubungan antara jenis kelamin dengan tipe belanja. Pada tabel di atas dapat dilihat terdapat perbedaan antara jenis kelamin wanita dan laik-laki untuk tipe belanja, perbedaan yang cukup nyata terdapat pada tipe belanja sebulan sekali untuk wanita dan laki-laki.
Selain asumsi homogenitas varians dengan uji Levene's test, perlu dilakukan juga uji asumsi residual dari model yang mengikuti distribusi normal. Pengujian dilakukan dengan menggunakan uji Kolmogorov smirnov. Langkah pengujia sebagai berikut :
- Buka kembali file data di SPSS, pada analisis pertama dilakukan langkah save pada standardized sehingga akan muncul kolom baru ZRE_1 pada variabel view.
- Klik Analyze > Non parametric test > 1 sample KS
- Masukkan variabel ZRE_1 ke kolom variabel test.
- Kemudian OK.
 |
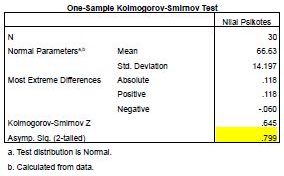
Kolmogorov Smirnov
|
Hasil uji kolmogorov smirnov memberikan nilai sebesar 0,900 dengan signifikansi 0,393. Karena nilai signifikansi 0,393 > 0,05 maka terbukti bahwa nilai residual berdistribusi normal.
Baca juga :
One Way ANOVA
Langkah Analisis Regresi Logistik
Langkah Analisis Manova dengan SPSS
Cara Uji Regresi Ordinal dengan SPSS
Referensi :
Cortina,J.M and Nouri,H. (2000). Effect Size for Anova Designs.London New Delhi: Sage Publications Inc
Field,A. (2009). Discovering Statistics Using SPSS 3rd. London: Sage Publications
Hair,J.F,.Black,W.C.,Babin,B.J.,and Anderson,R.E. (2009). Multivariate Data Analysis 7th Edition.Prentice Hall
Rutherford, A. (2001). Introducing Anova and Ancova a GLM Approach. London New Delhi : Sage Publications Inc
Tabanick,B.G and Fidel,L.S.(2007).Using Multivariate Statistics 5th.New York: Pearson Education
Yang,K and Trewn,J.(2004).Multivariate Statistical Methods In Quality Management.MC Graw Hill Engineering






































{kind=link}