
Analisis K-Mean Kluster bertujuan untuk mengelompokkan obyek berdasarkan ciri-ciri yang dimiliki atau karekateristik yang dimiliki. Pengelompokkan obyek ini bisa berdasarkan ciri-ciri pada responden atau produk dan entitas lainnya, sehingga obyek tersebut memiliki kemiripan yang sama dalam satu kluster. Hasil analisis kluster dari sebuah obyek akan memiliki kesamaan (homogenitas) yang tinggi dalam 1 kluster yang sama dan memiliki ketidaksamaan (heterogenitas) dengan kluster yang lain.

Contoh kasus
Sebuah pusat pembelanjaan melakukan riset untuk mengtahui apa saja yang mendorong konsumen/pembeli berbelanja di Swalayan tersebut. variabel-variabel pertanyaan yang diajukan ke konsumen yaitu : lokasi toko, harga produk, kebersihan, pelayanan kasir, fasilitas dan keindahan interior swalayan. Untuk itu setiap responden diberi 6 pertanyaan dan didapat 20 responden sebagai sampel. Data yang diperoleh sebagai berikut :
 |
| Data Input |
Dari data tersebut pertama dilakukan nilai standarkan terlebih dahulu dengan membuat nilai z-score, dengan cara:
- Klik Analyze >Descriptive statistics > Descriptives
- Pindahkan variabel-variabel tersebut ke kolom variable (s)
- Aktifkan Save standardized values as variables
- Klik OK
 |
| Descriptive Statistics |
Perhatikan bahwa nilai deskriptif pada tabel di atas berguna dalam membantu pengelompokan kluster nantinya. Nilai mean/rata-rata penilaian responden terhadap faktor-faktor pada swalayan tertinggi pada faktor keindahan interior sebesar 4.35, kemudian harga produk dan pelayanan kasir masing-masing 4.10, kebersihan 3.95, lokasi toko 3.85 dan terendah pada fasilitas hanya 3.45.
 |
| Nilai Z score dari variabel |
Hasil nilai z-score terlihat pada tabel dengan awalan Z, nilai ini yang nantinya sebagai data input yang akan dianalisis.
Kemudian langkah analisis K-Mean Cluster dalam SPSS:
- Pilih Analyze > Classify > K-Mean Cluster
- Pindahkan variabel z-core yang berawalan "z" ke kolom variable (s)
- Tentukan jumlah kluster dengan mengisikan angka 3 pada Number of Clusters
- Pilih Save dan aktifkan Cluster Membership dan distance from cluster centre, kemudian Continue
- Pilih Option, aktifkan Initial Cluster dan Anova Table
- Tekan OK.
Hasil Ouput K-Mean Cluster dari SPSS
 |
| Initial Cluster Centers |
Pada tabel Initial cluster Centers menunjukan hasil proses sementara pengelompokan data yang dilakukan. Karena proses ini baru awal maka perlu dilakukan proses selanjutnya.
 |
| Iteration History |
Pada tabel Iteration history. metode K-Mean Cluster akan menguji dan realokasi kluster yang ada. Proses tersebut dinamakan iteration yang memuat perubahan pada initial cluster (change in cluster). Proses ini pengelompokan diulang dengan ketepatan yang lebih akurat.
 |
| Cluster Membership |
Pada cluster mebership memberikan petunjuk bahwa tiap responden masuk ke dalam masing-masing cluster yang dibentuk. Seperti responden 1 masuk kluster 3, responden 2 masuk kluster 2 dan responden 4 masuk kluster 1. Namun pengelompokan ini masih tahap awal, perlu dianalisis lebih lanjut.
 |
| Final Cluster Centers |
Tabel final clster centers menunjukan hasil analisisnya untuk masing-masing variabel dan kluster yang dibentuk. Pedoman untuk menafsirkan tabel hasil analisis dengan ketentuan sebagai berikut :
- Jika hasil perhitungan ditemukan hasil negatif berarti kluster yang bersangkutan ada di bawah rata-rata total.
- Jika hasil perhitungan ditemukan hasil positif berarti kluster yang bersangkutan ada di atas rata-rata total.
Contoh perhitungan untuk angka skor variabel lokasi toko pada kluster 1, 2 dan 3.
Dimana :
X = rata-rata sampel/data/variabel dalam kluster tertentu
= rata-rata populasi
= standard deviasi
 |
| Hitung Skor variabel pada tiap Kluster |
Perhitungan manual di atas hanya sebagai gambaran/contoh, untuk variabel 1 (lokasi toko). Untuk variabel yang lain dapat dilakukan perhitungan sesuai dengan rumus di atas.
Penafsiran untuk variabel 1 (lokasi toko) adalah :
- Kluster 1 nilai rata-rata 3,50009 lebih kecil/rendah dari rata-rata populasi 3,85, hal ini berarti responden tidak menyukai lokasi swalayan.
- Kluster 2 nilai rata-rata 1,667175 lebih rendah dari rata-rata populasi 3,85, hal ini berarti responden tidak menyukai lokasi swalayan.
- Kluster 3 nilai rata-rata 5,7405481 lebih tinggi dari rata-rata populasi 3,85, hal ini berarti responden menyukai lokasi swalayan.
Namun secara cepat hasilnya dapat diketahui dari nilai tiap variabel (tanda - dan +) pada tabel final cluster centers. Dengan memperhatikan tanda tersebut dapat diketahui tiap variabel masuk ke dalam kluster mana?. Sesuai dengan pedoman penafsiran tabel analisis di atas. Variabel 1 (lokasi toko) masuk Kluster 3, variabel 2 (harga produk) masuk Kluster 1, variabel 3 (kebersihan) masuk Kluster 4, variabel 4 (pelayanan kasir) masuk Kluster 1, variabel 5 (fasilitas) masuk Kluster 2 dan variabel 6 (keindahan interior)masuk Kluster 1.
 |
| Distance between Final Cluster Centers |
Tabel Distances between final cluster centers menunjukkan jarak antar kluster, semakin besar nilai/angka maka semakin besar/lebar jarak antar kluster. Kluster 1 berjarak dengan kluster 2 sebesar 3,563 dan dengan kluster 3 sebesar 3,473. Jarak kluster 2 dengan kluster 1 sebesar 3,563 dan dengan kluster 3 sebesar 3,679. Jarak kluster 3 dengan kluster 1 sebesar 3,473 dan dengan kluster 2 sebesar 3,679.
 |
| Uji F Anova |
Sekarang kita akan menguji apakah masing-masing kluster berbeda secara signifikan. Pengujian dilakukan dengan melihat nilai F dan signifikansinya pada tabel Anova. Untuk mempermudah kita menggunakan p-value signifikansi. Pengujian hipotesisnya sebagai berikut :
H0 = Ketiga kluster tidak ada perbedaan yang signifikan
H1 = Ketiga kluster ada perbedaan yang signfikan
Tolak hipotesis nol (H0) jika nilai p-value <0.05
Pada tabel Anova di atas menunjukan nilai p-value pada keenam variabel lokasi toko sebesar 0.000, harga produk 0.000, kebersihan 0.000, pelayanan kasir 0.000, fasilitas 0.000, fasilitas 0.000 dan keindahan interior sebesar 0.000. Sehingga dapat disimpulkan bahwa keenam variabel tersebut ada perbedaan yang signifikan karena nilai p-value yang didapat <0.05.
 |
| Number of Cases in each Cluster |
Tabel Number of caes in each cluster, memberikan gambaran jumlah responden yang masuk ke dalam tiap-tiap kluster. Kluster 1 ada 6 responden, kluster 2 ada 6 responden dan kluster 3 ada 8 responden.
Hasil secara keseluruhan analisis k-mean cluster dapat dirangkum dalam bentuk tabel excel di bawah ini.
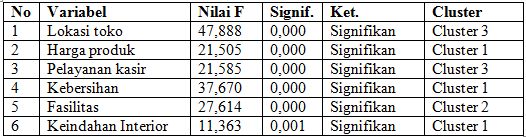 |
| Rangkuman Hasil K-Mean Cluster |
Baca juga :
3. Langkah Analisis Korespondensi dengan SPSS
Referensi :
Abony,J dan Feil,B. (2007). Cluster Analysis for Data Mining and System Identification.Boston Berlin: Birkhauser Verlag
Field,A. (2005). Discovering Statistics Using SPSS 2rd. London: Sage Publications
Hair,J.F,.Black,W.C.,Babin,B.J.,and Anderson,R.E. (2009). Multivariate Data Analysis 7th Edition.Prentice Hall
Kaufman,L and Rousseeuw,P.J. (2005). Finding Groups In data An Introduction to Cluster Analysis.New Jersey: John Wiley & Sons