Analisis regresi berganda merupakan teknik statistik yang sudah dikenal luas pada berbagi bidang seperti ilmu sosial, psikologi, ekonomi, manajemen dan lain sebagainya. metode Regresi dapat mengestimasikoefiisen persamaan regresi dan pengaruh variabel independen (bebas) terhadap variabel dependen (terikat). Seperti kita ketahui bahwa Lisrel sebagai program aplikasi Structural Equation Modeling (SEM) yang mampu untuk menyelesaikan model SEM secara full model yaitu dengan mengestimasi model dengan variabel laten dan variabel manifest (indikator).Selain itu Lisrel juga dapat mengestimasi model regresi yang dalam model tersebut hanya memerlukan variabel-variabel manifest (pengukur langsung) baik pada variabel independen maupun dependen. Yang mana hasil akan berbeda dengan model regresi yang menggunakan estimasi Ordinary Least square (OLS). Pada model regresi dengan Lisrel teknik estimasi mengggunakan Maximum Likelihood (ML).

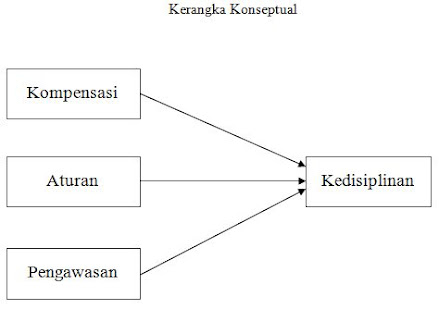
Pada kesempatan kali ini saya memberikan contoh model regresi dengan 3 variabel independen yaitu Kepuasan Kerja (KK), Quality of Network (QW), Budaya Organisasi (BO) dan Motivasi kerja (MO) sebagai variabel dependennya. Kerangka konsep sebagai berikut :
 |
Konseptual model regresi Motivasi Kerja
|
Dari konsep model tersebut dibuat 3 hipotesis :
- Kepuasan Kerja (KK) berpengaruh terhadap Motivasi kerja (MO)
- Quality of Network (QW) berpengaruh terhadap Motivasi kerja (MO)
- Budaya Organisasi I (BO) berpenaruh terhadap Motivasi kerja (MO)
Langkah Analisis regresi dengan Lisrel
Siapkan data input (raw data) dalam format ms.excel atau *sav (SPSS). Kemudian Import data ke dalam aplikasi Lisrel dan simpan dalam folder (saya simpan di folder D:/Kinerja/Data) kemudian lakukan screening data untuk menguji normalitas univariat dan multivariate.
 |
Screening normalitas data
|
Hasil screening data menunjukkan bahwa nilai p-value skewness dan kurtosis dari masing-masing variabel KK sebesar 0.635, QW sebesar 0.519, BO sebesar 0.530 dan MO sebesar 0.680. Hasil ini membuktikan bahwa ke empat variabel tersebut berdistribusi normal multivariat karena nilai p-value < 0.05. Pas test of multivariate normality, terlihat bahwa nilai chi-square sebesar 3.602 dan p-value dari skewness dan kurtosis menunjukkan nilai sebesar 0.165. Karena nilai 0.165 > 0.05 maka terbukti bahwa data berdistribusi normal multivariate.
Selanjutnya membuat Simplis Project.
Klik File -->New --> Simplis Project --> OK, beri nama : Kinerja
Ketik perintah/syntax di simplis project seperti di bawah ini :
Raw data from file 'D:/Kinerja/Data.psf'
Relationships
Path Diagram
MO = Constan KK QW BO
End of Problem
Baris ke-1 : informasi di mana data mentah (raw data) disimpan yang akan di baca oleh program prelis.
Baris ke-2 : pembatas bahwa informasi mengenai hubungan-hubungan antara variabel terletak setelah relationships.
Baris ke-3 : informasi mengenai persamaan yang akan diestimasi. variabel dependen ditulis di sebelah kanan dan independen ditulis sebelah kiri setelah tanda sama dengan.
Hasil akan terlihat seperti ini.
 |
Syntax Lisrel
|
Setelah selesai membuat syntax langkah terakhir melakukan running dengan cara : klik Run Lisrel.
Hasil estimasi dan model yang terbentuk terlihat di bawah ini
 |
Model regresi pada Lisrel
|
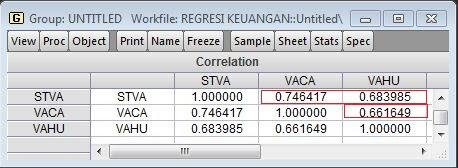
Hasil output matrik kovarian dari variabel.
 |
Covariance MAtrix of Latent variables
|
Pada tabel covariance matrix di atas merupakan hasil dari data mentah sebagai input data dinamakan juga matrik varians kovarian. Matrik varian kovarian yang terbentuk untuk nilai varian pada masing-masing variabel membentuk garis diagonal, varians MO sebesar 9.91, KK 21.92, QW 12.34, dan BO 1.49. Sedangakan nilai-nilai yang lain merupakan nilai kovarian antar variabel. Oleh sebab itu dinamakan matrik varian kovarian.
 |
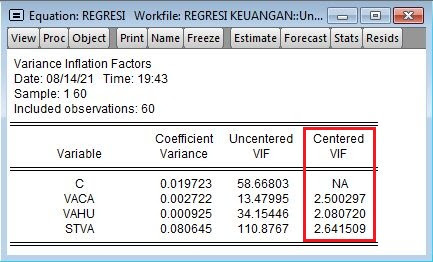
Structural Equations
|
Pada tabel Structural Equation terlihat bahwa nilai estimasi koefisien pengaruh Kepuasan kerja (KK) sebesar 0.13 dengan nilai eror 0.084 dan nilai t-statistik sebesar 1.59. Nilai estimasi koefisien pengaruh Quality of network (QW) sebesar 0.32, nilai eror 0,11 dan nilai t-statistik sebesar 2.97. Sedangkan untuk b udaya Organisasi (BO) nilai koefisien pengaruh sebesar 0.23, nilai eror 0.097 dan nilai t-statistik 2.41. Dari hasil tersebut hanya variabel Kepuasan kerja yang tidak berpengaruh signifikan terhadap Motivasi Kerja (MO) karena nilai t-statistik yang diperoleh sebesar 1.59 < 1.96 t-tabel pada taraf signifikansi 5%. Sedangkan Quality of Network (QW) dan Budaya Organisasi (BO) berpengaruh signifikan terhadap Motivasi Kerja (MO) karena nilai t-statistik > 1.96 t-tabel.
Nilai konstanta (intercept) sebesar 18.08, nilai konstanta ini dapat diartikan seperti pada model regresi pada umumnya, bahwa nilai motivasin kerja (MO)n sebesar 18.08 apabilai keluasan kerja, Quality of network dan budaya Organisasi sebesar 0 (nol). Lisrel output akan menampilkan nilai konstanta (intercept) jika input data adalah data mentah (raw data) dan memasukan perintah "constant" di simplis project. Tetapi jika input data dalam covariance matrix nilai kostanta akan ditampilkan output lisrel jika memasukkan data "Mean".
Nilai R-square yang diperoleh Motivasi kerja (MO) sebesar 0.47, artinya bahwa Kepuasan Kerja, Quality of Network dan Budaya Organisasi mampu menjelaskan variasi pada motivasi kerja sebesar 47% (0.47 x 100%).
 |
| Goodness Of Fit Statistics |
|
Pada nilai Goodness of fit menunjukkan bahwa degree of freedom (df) sebesar 0 (nol) karena antara jumlah dinsting sampel dan jumlah dinsting parameter yang diestimasi berjumlah sama. Nilai chi-square sebesar 0 dengan nilai p-value sebesar 1.00 dan model dinyatakan "The fit is perfect".
Baca juga :
Model regresi berganda dengan AMOS
Evaluasi Asumsi pada Model SEM
Uji Kesesuaian Fit Model SEM
Referensi :
Byrne, B.M.(1998).Structural Equation Modeling With Lisrel, Prelis and Simplis: basic Concepts, Applications and Programing. New Jersey: Lawrence Erlabaum Associates,Inc
Hoyle,R.H.(2012).Handbook of Structural Equation Modeling.New York and London : The Guillford Press
Ghozali,I dan Fuad.(2014). Structural Equation Modeling : Teori, Konsep dan Aplikasi dengan Program Lisrel 9.10 Edisi 4. Semarang : Badan Penerbit Universitas Diponegoro
Mueller,R.O.(1996). Basci Principles of Structural Equation Modeling :An Introduction to Lisrel and EQS.New York: Springer-Verlag,Inc
















































{kind=link}
{kind=link}